 公众号
公众号NVIDIA CUDA 4.0 RC版发布 新特性解析
2011-03-15 18:49:03
- +1 你赞过了
【天极网DIY硬件频道】首次宣布一周之后,NVIDIA今天公开发布了GPU通用计算开发包的CUDA 4.0 RC候选版,并提供给开发人员下载使用。
如果你是一位GPU计算开发人员,或者对这方面有兴趣,可以在NVIDIA官方网站上注册并获得这个新的开发包,地址为:
//developer.nvidia.com/object/cuda_4_0_RC_downloads.html
CUDA 4.0作为一个全新版本,功能特性自然增加了不少,主要涉及应用程序移植的简化、多GPU编程的加速、开发工具的增加和改进三个方面。下边我们就结合NVIDIA的官方演示文稿,一起看看CUDA 4.0的新特性。

从超级手机到超级计算机:NVIDIA正在将自己定位成一家“超级”计算公司,CUDA 4.0就是这条路上的重要里程碑。

CUDA发展之路:2007年1.0版,只有研究人员和一些尝鲜者体验;次年升级为2.0版,吸引了科学家和高性能计算领域;2009年3.0版,掀起了应用程序创新的风潮;如今4.0版诞生,意味着将有更广泛的开发人员加入CUDA阵营。
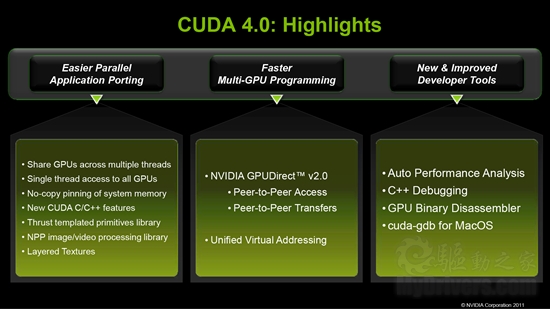
CUDA 4.0三大进步:应用程序移植的简化、多GPU编程的加速、开发工具的增加和改进。

为了简化应用程序的移植,CUDA 4.0带来了统一虚拟寻址(UVA)、GPUDirect 2.0、Thrust C++模板化算法与数据结构。

CUDA 4.0支持多个线程共享一个或者多个GPU,同时单个主线程也可以访问所有GPU,可以充分发挥多GPU的联合优势,即使是单线程程序也能从多GPU中获得更好性能。

无需拷贝的映射机制(No-copy Pinning),减少系统内存占用、避免过载,并且支持Windows、Linux系统和所有CUDA GPU。
C/C++语言方面也增加了新特性,包括新建/删除、虚拟功能和Inline PTX等等。

Thrust C++模板化算法与数据结构,强大的开源C++并行算法和数据结构,类似C++ STL标准模板库;可在编译时自动选择最快的代码路径,在多核心CPU与GPU之间分配工作,编译速度加快5-10倍。

GPU加速图形处理:全新的NVIDIA Performance Primitives NPP函数库,图像处理加速10-36倍。

层纹理:适合以标准尺寸、格式处理多重纹理,性能更快,而且不会出现采样残影。

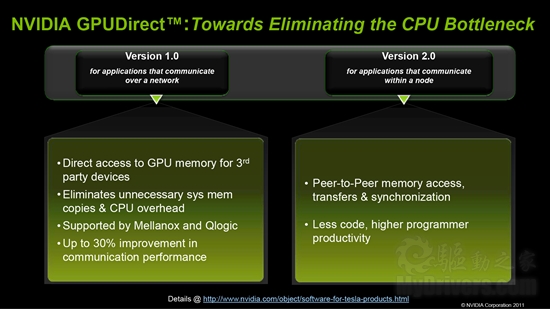
旧版的GPUDirect 1.0侧重于改进网络间通信,2.0版则侧重于改进节点内通信效率,支持P2P内存访问、传输和同步,代码更少,编程效率更高。
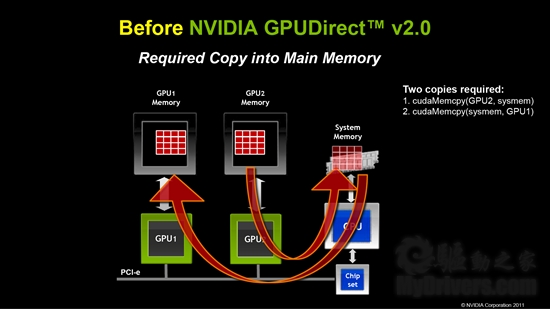
在此之前,同一节点内的不同GPU互相访问,需要绕道系统内存并进行两次拷贝。
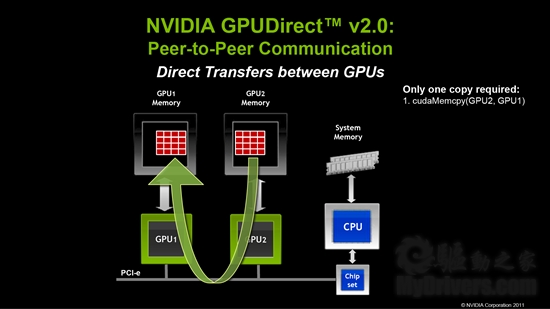
现在就不用理会系统内存了,不同GPU可以直接进行传输,一次拷贝搞定。

不过要注意,GPUDirect 2.0仅支持Fermi费米架构的Tesla 20系列高性能计算卡,而且需要64位的Linux、Windows操作系统。
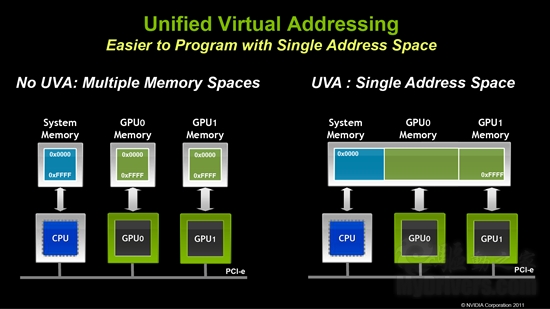
统一虚拟寻址:之前系统内存、GPU显存都是彼此互相独立的,现在则融合在一起,为所有CPU、GPU提供单个统一的寻址空间。

但是这项技术也有同样的限制,只适用于Fermi Tesla 20系列和64位系统。
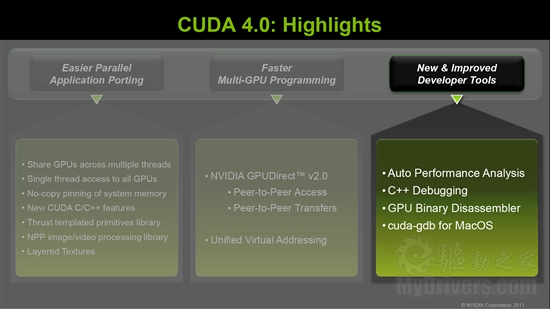
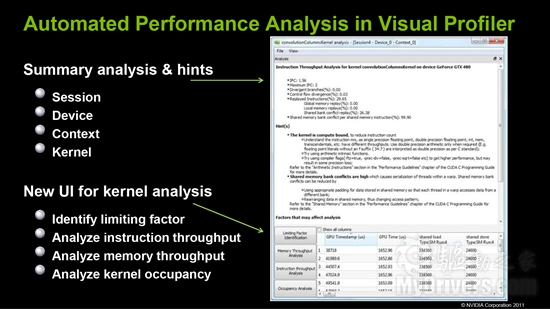
开发工具方面首先是可视化编译器的自动性能分析,并为内核分析提供了新的用户界面。
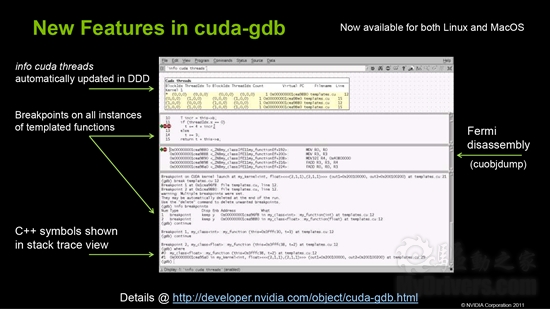
cuda-gdb调试同样增加了大量新功能,尤其是Fermi架构支持GPU Binary反汇编。
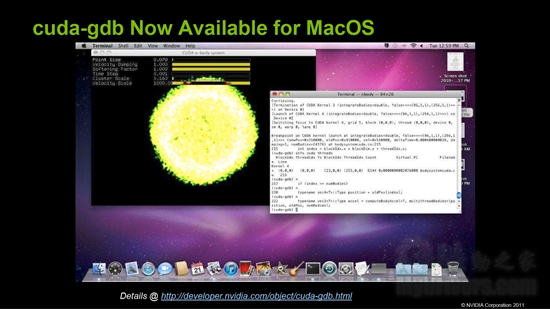
而且操作系统支持在Linux的基础上增加了苹果Mac OS。
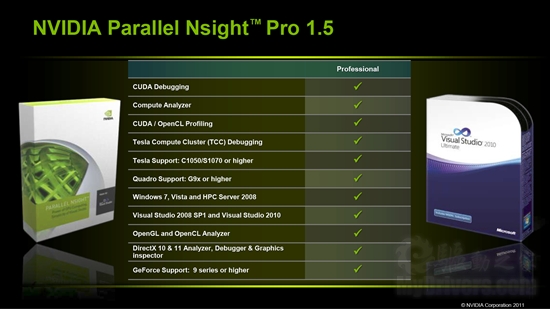
此外NVIDIA还提供了新的专业开发工具Parallel Nsight Pro 1.5,这是业界第一个针对微软Visual Studio的GPU加速应用开发环境。

CUDA特性总览

CUDA注册开发人员项目

NVIDIA CUDA开发资源
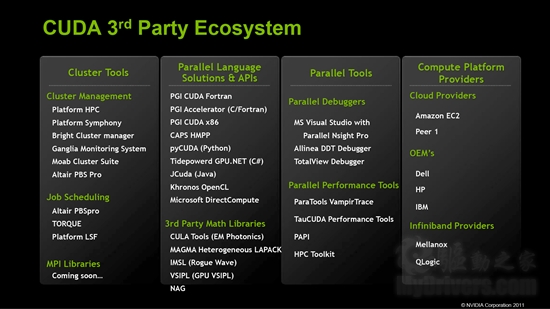
CUDA第三方生态系统

CUDA计算研究与教育

PGI CUDA-x86编译器

GTC 2011技术大会

驱动之家
最新资讯
热门视频
新品评测
 X
X

 微博认证登录
微博认证登录
 QQ账号登录
QQ账号登录
 微信账号登录
微信账号登录

+1 你赞过了